![]() ## packageRank: compute and visualize package download counts and rank percentiles
## packageRank: compute and visualize package download counts and rank percentiles
‘packageRank’ is an R package that helps put package download counts into context. It does so via two core functions, cranDownloads() and packageRank(), a set of filters that reduce download count inflation, and a host of other assorted functions.
You can read more about the package the sections below:
cranDownloads() gives cranlogs::cran_downloads() a more user-friendly interface, and how it makes visualizing those data easy (via a generic R plot() method).packageRank() makes use of rank percentiles. This nonparametric statistic computes the percentage of packages that with fewer downloads than yours (e.g., your package is in the 74th percentile). This facilitates comparison and helps you to locate you packaged in the overall distribution of CRAN package downloads.packageRank() and packageLog() but not, for computational reasons, in cranDownloads().logInfo() to check the availability of today’s results, and the effect of time zones.fixDate_2012() and fixCranlogs().fixRCranlogs().countryPackage() and packageCountry()), the use of memoization, the internet connection time out problem, and the spikes in the download of the Windows version of the R application on Sundays and Wednesdays between 06 November 2022 and 19 March 2023.To install ‘packageRank’ from CRAN:
To install the development version from GitHub:
# You may need to first install 'remotes' via install.packages("remotes").
remotes::install_github("lindbrook/packageRank", build_vignettes = TRUE)cranDownloads() uses all the same arguments as cranlogs::cran_downloads():
> date count package
> 1 2020-05-01 338 HistDataThe only difference is that cranDownloads() adds four features:
## Error in cranDownloads(packages = "GGplot2") :
## GGplot2: misspelled or not on CRAN.> date count cumulative package
> 1 2020-05-01 56357 56357 ggplot2
Note that his also works for inactive or “retired” packages in the Archive:
## Error in cranDownloads(packages = "vr") :
## vr: misspelled or not on CRAN/Archive.> date count cumulative package
> 1 2020-05-01 11 11 VRWith cranlogs::cran_downloads(), you specify a time frame using the from and to arguments. The downside of this is that you must use “yyyy-mm-dd”. For convenience’s sake, cranDownloads() also allows you to use “yyyy-mm” or yyyy (“yyyy” also works).
Let’s say you want the download counts for ‘HistData’ for February 2020. With cranlogs::cran_downloads(), you’d have to type out the whole date and remember that 2020 was a leap year:
With cranDownloads(), you can just specify the year and month:
Let’s say you want the download counts for ‘rstan’ for 2020. With cranlogs::cran_downloads(), you’d type something like:
With cranDownloads(), you can use:
or
from = and to = in cranDownloads()These additional date formats help to create convenient shortcuts. Let’s say you want the year-to-date download counts for ‘rstan’. With cranlogs::cran_downloads(), you’d type something like:
With cranDownloads(), you can just pass the current year to from =:
And if you wanted the entire download history, pass the current year to to =:
Note that because the Posit/RStudio logs begin on 01 October 2012, download data for packages published before that date are unavailable.
## Error in resolveDate(to, type = "to") : Not a valid date.> date count cumulative package
> 1 2020-05-01 338 338 HistData
> 2 2020-05-02 259 597 HistData
> 3 2020-05-03 321 918 HistData
> 4 2020-05-04 344 1262 HistData
> 5 2020-05-05 324 1586 HistData
> 6 2020-05-06 356 1942 HistData
> 7 2020-05-07 324 2266 HistDatacranDownloads() makes visualizing package downloads easy. Just use plot():
If you pass a vector of package names for a single day, plot() returns a dotchart:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020-03-01", to = "2020-03-01"))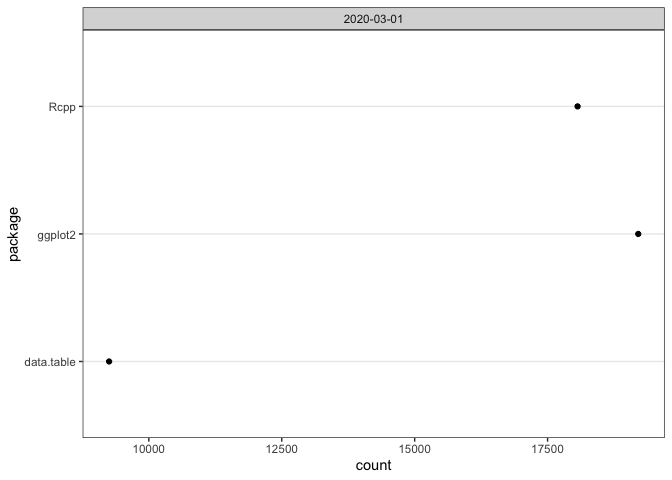
If you pass a vector of package names for multiple days, plot() uses ‘ggplot2’ facets:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"))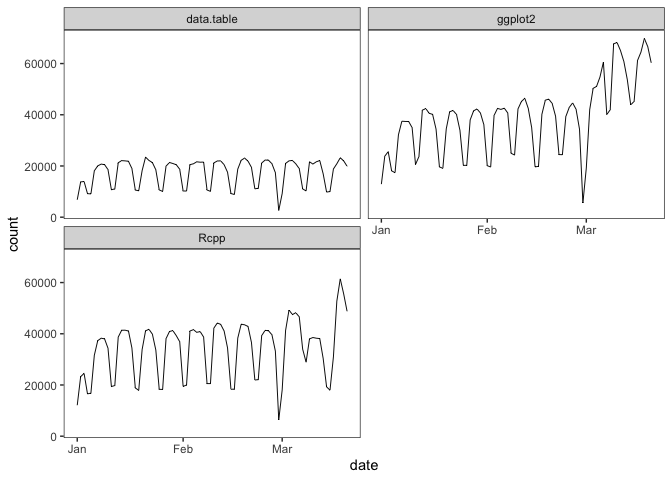
To plot those data in a single frame, set multi.plot = TRUE:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"), multi.plot = TRUE)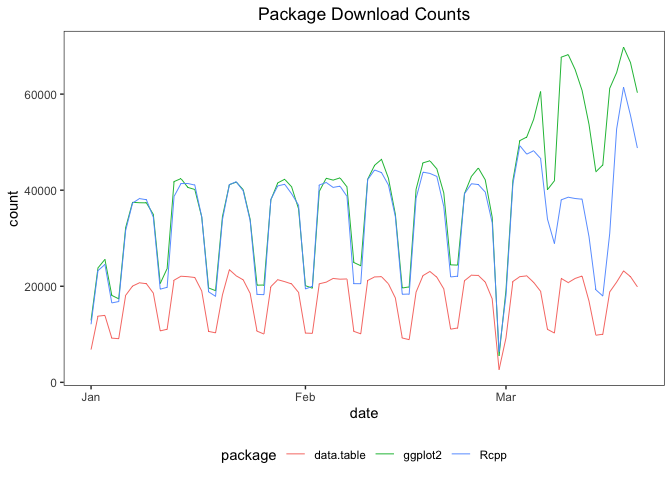
To plot those data in separate plots on the same scale, set graphics = "base" and you’ll be prompted for each plot:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"), graphics = "base")To do the above on separate, independent scales, set same.xy = FALSE:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"), graphics = "base", same.xy = FALSE)To use the base 10 logarithm of the download count in a plot, set log.y = TRUE:
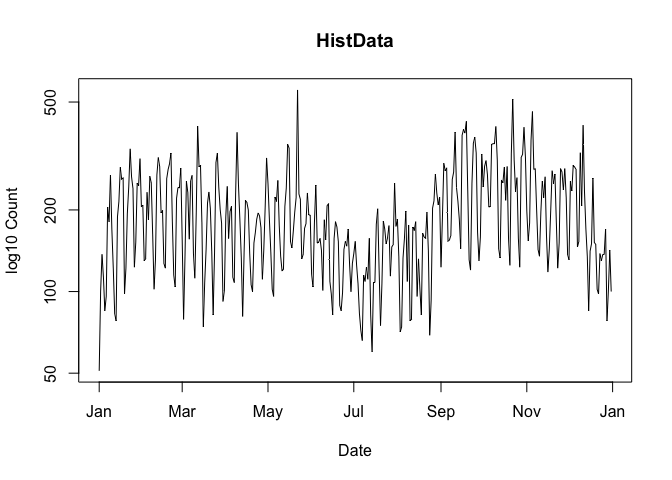
Note that for the sake of the plot, zero counts are replaced by ones so that the logarithm can be computed (This does not affect the data returned by cranDownloads()).
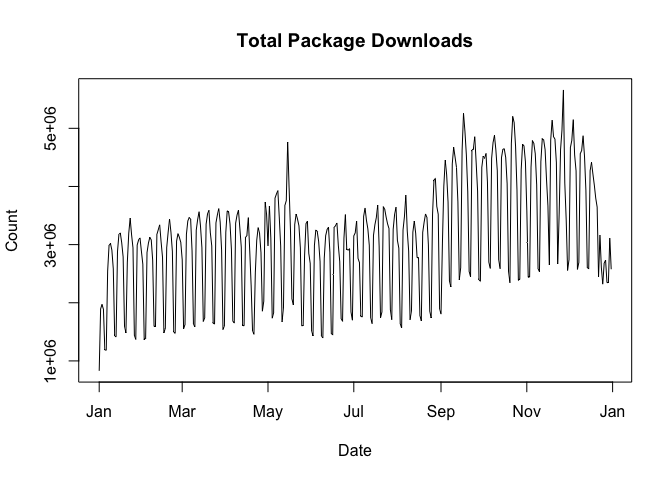
packages = NULLcranlogs::cran_download(packages = NULL) computes the total number of package downloads from CRAN. You can plot these data by using:
packages = "R"cranlogs::cran_download(packages = "R") computes the total number of downloads of the R application (note that you can only use “R” or a vector of packages names, not both!). You can plot these data by using:

If you want the total count of R downloads, set r.total = TRUE:
Note that since Sunday 06 November 2022 and Wednesday, 18 January 2023, there’ve been spikes of downloads of the Windows version of R on Sundays and Wednesdays (details below in R Windows Sunday and Wednesday downloads).
To add a lowess smoother to your plot, use smooth = TRUE:
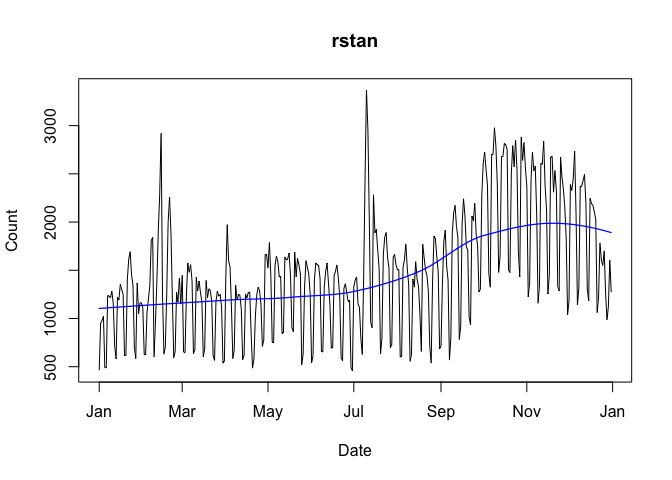
With graphs that use ‘ggplot2’, se = TRUE will add confidence intervals:
plot(cranDownloads(packages = c("HistData", "rnaturalearth", "Zelig"),
from = "2020", to = "2020-03-20"), smooth = TRUE, se = TRUE)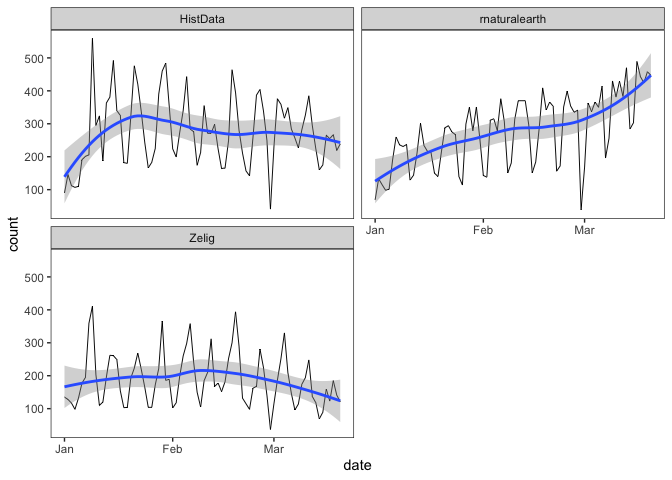
You can control the degree of smooth using the span argument (the default is span = 0.75):
plot(cranDownloads(packages = c("HistData", "rnaturalearth", "Zelig"),
from = "2020", to = "2020-03-20"), smooth = TRUE, se = TRUE, span = 0.33)To annotate a graph with a package’s release dates:
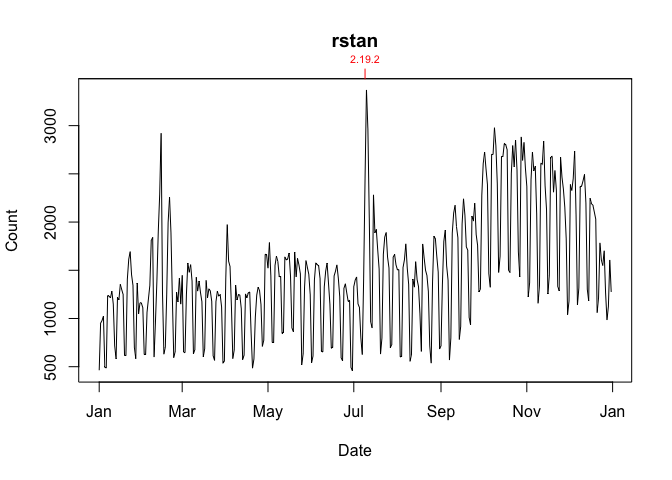
To annotate a graph with R release dates:
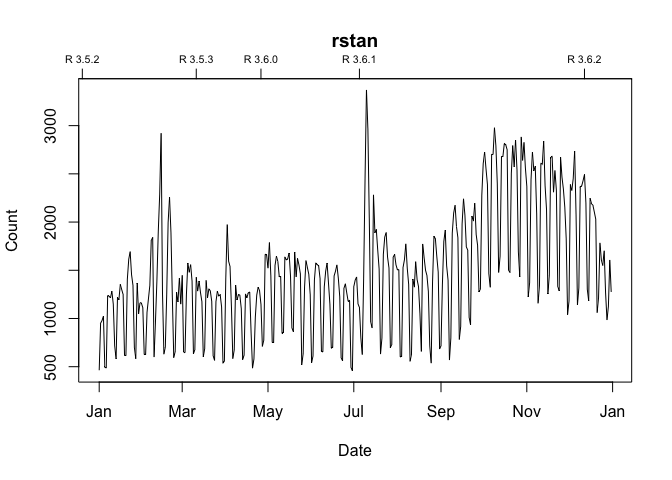
To plot growth curves, set statistic = "cumulative":
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"), statistic = "cumulative",
multi.plot = TRUE, points = FALSE)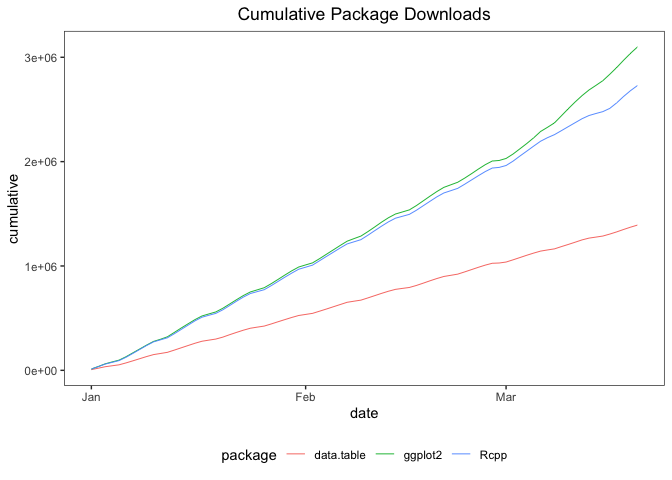
To visualize a package’s downloads relative to “all” other packages over time:
plot(cranDownloads(packages = "HistData", from = "2020", to = "2020-03-20"),
population.plot = TRUE)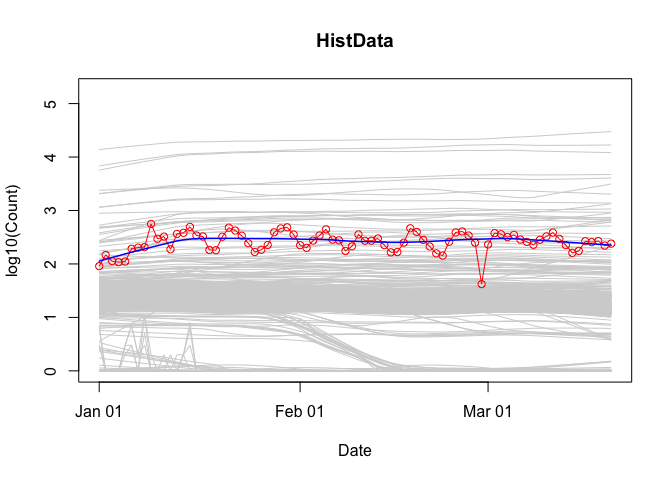
This longitudinal view of package downloads plots the date (x-axis) against the base 10 logarithm of the selected package’s downloads (y-axis). To get a sense of how the selected package’s performance stacks up against all other packages, a set of smoothed curves representing a stratified random sample of packages is plotted in gray in the background (the “typical” pattern of downloads on CRAN for the selected time period). Specifically, within each 5% interval of rank percentiles (e.g., 0 to 5, 5 to 10, 95 to 100, etc.), a random sample of 5% of packages is selected and tracked.
The unit of observation for both cranDownloads() and cranlogs::cran_dowanlods() is the “day”. The graph below plots the daily downloads for ‘cranlogs’ from 01 January 2022 through 15 April 2022.
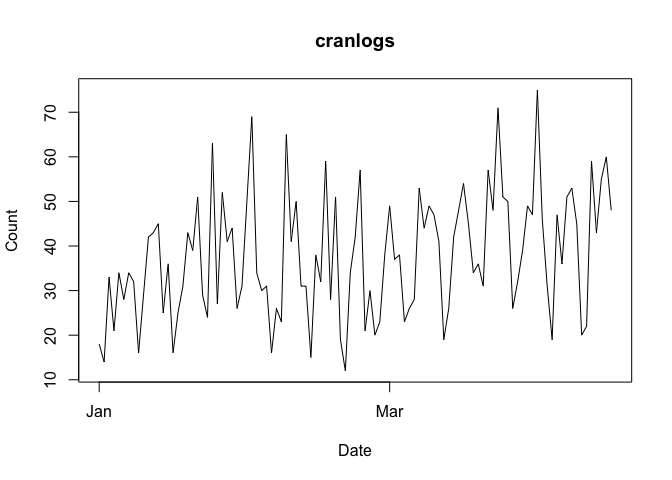
To view the data from a less granular perspective, set plot.cranDownloads()’s unit.observation argument to “week”, “month”, or “year”.
unit.observation = "month"The graph below plots the data aggregated by month (with an added smoother):
plot(cranDownloads(packages = "cranlogs", from = 2022, to = "2022-04-15"),
unit.observation = "month", smooth = TRUE, graphics = "ggplot2")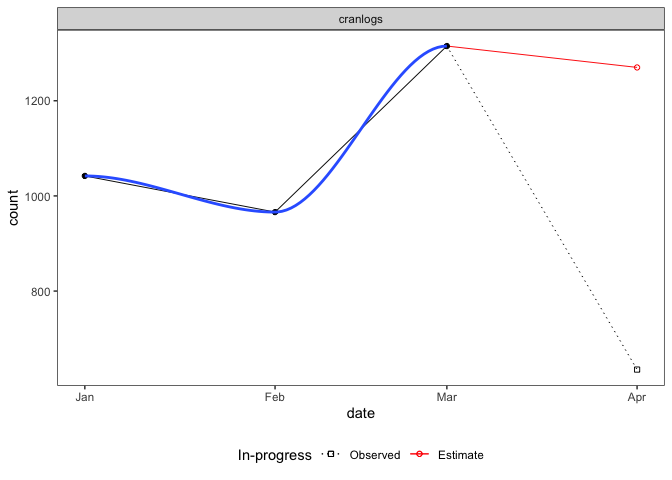
Three things to note. First, if the last/current month (far right) is still in-progress (it’s not the end of the month), that observation will be split in two: one point for the in-progress total (empty black square), another for the estimated total (empty red circle). The estimate is based on the proportion of the month completed. In the example above, the 635 observed downloads from April 1 through April 15 translates into an estimate of 1,270 downloads for the entire month (30 / 15 * 635). Second, if a smoother is included, it will only use “complete”, not in-progress or estimated data. Third, all points are plotted along the x-axis on the first day of the month.
unit.observation = "week"The graph below plots the data aggregated by week (weeks begin on Sunday).
plot(cranDownloads(packages = "cranlogs", from = 2022, to = "2022-06-15"),
unit.observation = "week", smooth = TRUE)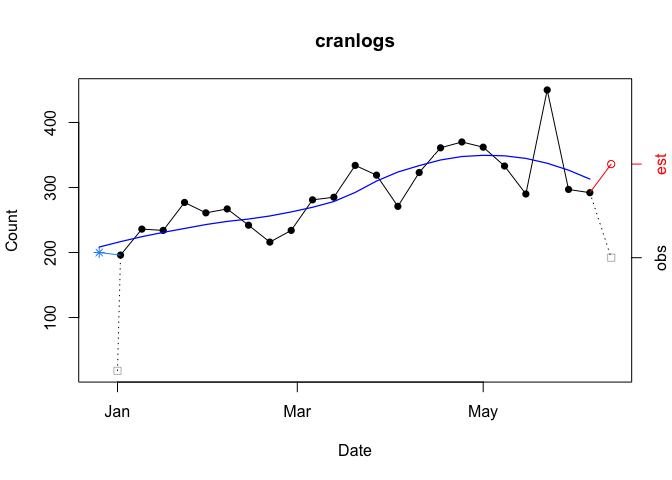
Four things to note. First, if the first week (far left) is incomplete (the ‘from’ date is not a Sunday), that observation will be split in two: one point for the observed total on the nominal start date (gray empty square) and another point for the backdated total. Backdating involves completing the week by pushing the nominal start date back to include the previous Sunday (blue asterisk). In the example above, the nominal start date (01 January 2022) is moved back to include data through the previous Sunday (26 December 2021). This is useful because with a weekly unit of observation the first observation is likely to be truncated and would not give the most representative picture of the data. Second, if the last week (far right) is in-progress (the ‘to’ date is not a Saturday), that observation will be split in two: the observed total (gray empty square) and the estimated total based on the proportion of week completed (red empty circle). Third, just like the monthly plot, smoothers only use complete data, including backdated data but excluding in-progress and estimated data. Fourth, with the exception of first week’s observed count, which is plotted at its nominal date, points are plotted along the x-axis on Sundays, the first day of the week.
After spending some time with nominal download counts, the “compared to what?” question will come to mind. For instance, consider the data for the ‘cholera’ package from the first week of March 2020:
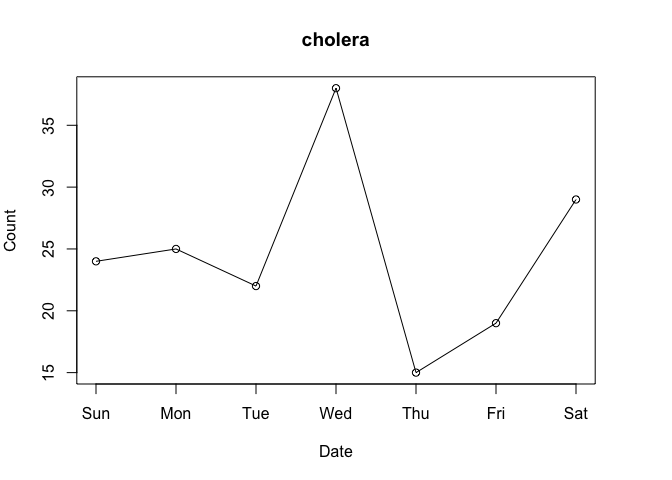
Do Wednesday and Saturday reflect surges of interest in the package or surges of traffic to CRAN? To put it differently, how can we know if a given download count is typical or unusual?
To answer these questions, we can start by looking at the total number of package downloads:
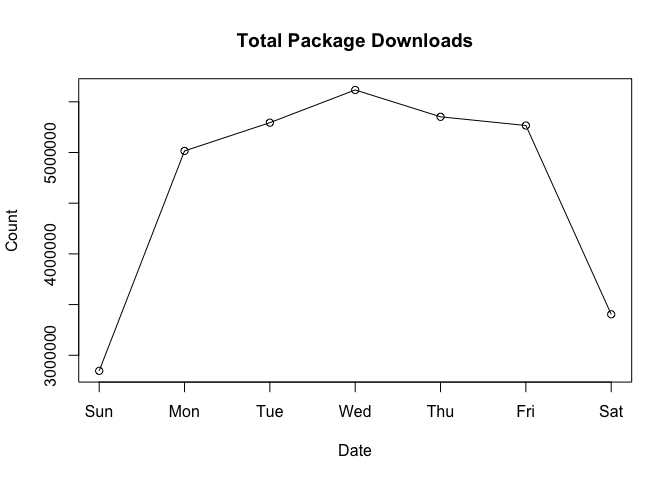
Here we see that there’s a big difference between the work week and the weekend. This seems to indicate that the download activity for ‘cholera’ on the weekend seems high. Moreover, the Wednesday peak for ‘cholera’ downloads seems higher than the mid-week peak of total downloads.
One way to better address these observations is to locate your package’s download counts in the overall frequency distribution of download counts. ‘cholera’ allows you to do so via packageDistribution(). Below are the distributions of logarithm of download counts for Wednesday and Saturday. Each vertical segment (along the x-axis) represents a download count. The height of a segment represents that download count’s frequency. The location of ‘cholera’ in the distribution is highlighted in red.

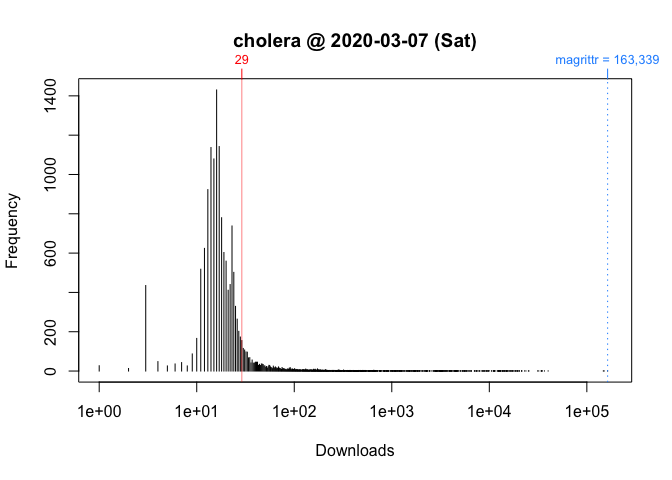
While these plots give us a better picture of where ‘cholera’ is located, comparisons between Wednesday and Saturday are still impressionistic: all we can confidently say is that the download counts for both days were greater than the mode.
To facilitate interpretation and comparison, I use the rank percentile of a download count instead of the simple nominal download count. This nonparametric statistic tells you the percentage of packages that had fewer downloads. In other words, it gives you the location of your package relative to the locations of all other packages. More importantly, by rescaling download counts to lie on the bounded interval between 0 and 100, rank percentiles make it easier to compare packages within and across distributions.
For example, we can compare Wednesday (“2020-03-04”) to Saturday (“2020-03-07”):
packageRank(package = "cholera", date = "2020-03-04")
> date packages downloads rank percentile
> 1 2020-03-04 cholera 38 5,556 of 18,038 67.9On Wednesday, we can see that ‘cholera’ had 38 downloads, came in 5,556th place out of the 18,038 different packages downloaded, and earned a spot in the 68th percentile.
packageRank(package = "cholera", date = "2020-03-07")
> date packages downloads rank percentile
> 1 2020-03-07 cholera 29 3,061 of 15,950 80On Saturday, we can see that ‘cholera’ had 29 downloads, came in 3,061st place out of the 15,950 different packages downloaded, and earned a spot in the 80th percentile.
So contrary to what the nominal counts tell us, one could say that the interest in ‘cholera’ was actually greater on Saturday than on Wednesday.
To compute rank percentiles, I do the following. For each package, I tabulate the number of downloads and then compute the percentage of packages with fewer downloads. Here are the details using ‘cholera’ from Wednesday as an example:
pkg.rank <- packageRank(packages = "cholera", date = "2020-03-04")
downloads <- pkg.rank$freqtab
round(100 * mean(downloads < downloads["cholera"]), 1)
> [1] 67.9To put it differently:
(pkgs.with.fewer.downloads <- sum(downloads < downloads["cholera"]))
> [1] 12250
(tot.pkgs <- length(downloads))
> [1] 18038
round(100 * pkgs.with.fewer.downloads / tot.pkgs, 1)
> [1] 67.9In the example above, 38 downloads puts ‘cholera’ in 5,556th place among 18,038 observed packages. This rank is “nominal” because it’s possible that multiple packages can have the same number of downloads. As a result, a package’s nominal rank but not its rank percentile can be affected by its name. For example, because packages with the same number of downloads are sorted in alphabetical order, ‘cholera’ benefits from the fact that it is 31st in the list of 263 packages with 38 downloads:
pkg.rank <- packageRank(packages = "cholera", date = "2020-03-04")
downloads <- pkg.rank$freqtab
which(names(downloads[downloads == 38]) == "cholera")
> [1] 31
length(downloads[downloads == 38])
> [1] 263To visualize packageRank(), use plot().
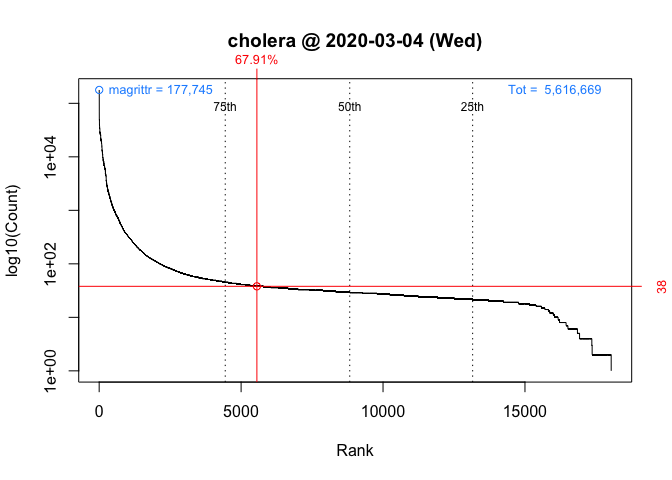
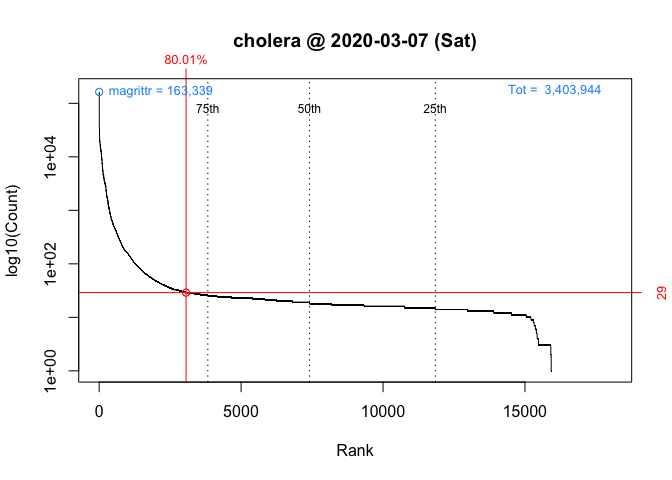
These graphs above, which are customized here to be on the same scale, plot the rank order of packages’ download counts (x-axis) against the logarithm of those counts (y-axis). It then highlights (in red) a package’s position in the distribution along with its rank percentile and download count. In the background, the 75th, 50th and 25th percentiles are plotted as dotted vertical lines. The package with the most downloads, ‘magrittr’ in both cases, is at top left (in blue). The total number of downloads is at the top right (in blue).
We compute the number of package downloads by simply counting log entries. While straightforward, this approach can run into problems. Putting aside the question of whether package dependencies should be counted, what I have in mind here is what I believe to be two types of “invalid” log entries. The first, a software artifact, stems from entries that are smaller, often orders of magnitude smaller, than a package’s actual binary or source file. The second, a behavioral artifact, emerges from efforts to download all of CRAN. In both cases, a reliance on nominal counts will give you an inflated sense of the degree of interest in your package. For those interested, an early but detailed analysis and discussion of both types of inflation is included as part of this R-hub blog post.
When looking at package download logs, the first thing you’ll notice are wrongly sized log entries. They come in two sizes. The “small” entries are approximately 500 bytes in size. The “medium” entries are variable in size: they fall somewhere between a “small” entry and a full download (i.e., “small” <= “medium” <= full download). “Small” entries manifest themselves as standalone entries, paired with a full download, or as part of a triplet along side a “medium” and a full download. “Medium” entries manifest themselves as either standalone entries or as part of a triplet.
The example below illustrates a triplet:
packageLog(date = "2020-07-01")[4:6, -(4:6)]
> date time size package version country ip_id
> 3998633 2020-07-01 07:56:15 99622 cholera 0.7.0 US 4760
> 3999066 2020-07-01 07:56:15 4161948 cholera 0.7.0 US 4760
> 3999178 2020-07-01 07:56:15 536 cholera 0.7.0 US 4760The “medium” entry is the first observation (99,622 bytes). The full download is the second entry (4,161,948 bytes). The “small” entry is the last observation (536 bytes). At a minimum, what makes a triplet a triplet (or a pair a pair) is that all members share system configuration (e.g. IP address, etc.) and have identical or adjacent time stamps.
To deal with the inflationary effect of “small” entries, I filter out observations smaller than 1,000 bytes (the smallest package on CRAN appears to be ‘source.gist’, which weighs in at 1,200 bytes). “Medium” entries are harder to handle. I remove them using either a triplet-specific filter or a filter that looks up a package’s actual size.
While wrongly sized entries are fairly easy to spot, seeing the effect of efforts to download all of CRAN require a change of perspective. While details and further evidence can be found in the R-hub blog post mentioned above, I’ll illustrate the problem with the following example:
> date time size package version country ip_id
> 132509 2020-07-31 21:03:06 3797776 cholera 0.2.1 US 14
> 132106 2020-07-31 21:03:07 4285678 cholera 0.4.0 US 14
> 132347 2020-07-31 21:03:07 4109051 cholera 0.3.0 US 14
> 133198 2020-07-31 21:03:08 3766514 cholera 0.5.0 US 14
> 132630 2020-07-31 21:03:09 3764848 cholera 0.5.1 US 14
> 133078 2020-07-31 21:03:11 4275831 cholera 0.6.0 US 14
> 132644 2020-07-31 21:03:12 4284609 cholera 0.6.5 US 14Here, we see that seven different versions of the package were downloaded as a sequential bloc. A little digging shows that these seven versions represent all versions of ‘cholera’ available on that date:
> Package Version Date Repository
> 1 cholera 0.2.1 2017-08-10 Archive
> 2 cholera 0.3.0 2018-01-26 Archive
> 3 cholera 0.4.0 2018-04-01 Archive
> 4 cholera 0.5.0 2018-07-16 Archive
> 5 cholera 0.5.1 2018-08-15 Archive
> 6 cholera 0.6.0 2019-03-08 Archive
> 7 cholera 0.6.5 2019-06-11 Archive
> 8 cholera 0.7.0 2019-08-28 CRANWhile there are “legitimate” reasons for downloading past versions (e.g., research, container-based software distribution, etc.), I’d argue that examples like the above are “fingerprints” of efforts to download CRAN. While this is not necessarily problematic, it does mean that when your package is downloaded as part of such efforts, that download is more a reflection of an interest in CRAN itself (a collection of packages) than of an interest in your package per se. And since one of the uses of counting package downloads is to assess interest in your package, it may be useful to exclude such entries.
To do so, I try to filter out these entries in two ways. The first identifies IP addresses that download “too many” packages and then filters out campaigns, large blocs of downloads that occur in (nearly) alphabetical order. The second looks for campaigns not associated with “greedy” IP addresses and filters out sequences of past versions downloaded in a narrowly defined time window.
To get an idea of how inflated your package’s download count may be, use filteredDownloads(). Below are the results for ‘ggplot2’ for 15 September 2021.
filteredDownloads(package = "ggplot2", date = "2021-09-15")
> date package downloads filtered.downloads inflation
> 1 2021-09-15 ggplot2 113842 58067 96.05While there were 113,842 nominal downloads, applying all the filters reduced that number to 57,951, an inflation of 96%.
Note that the filters are computationally demanding. Excluding the time it takes to download the log file, the filters in the above example take approximate 75 seconds to run using parallelized code (currently only available on macOS and Unix) on a 3.1 GHz Dual-Core Intel Core i5 processor.
There are 5 filters. You can control them using the following arguments (listed in order of application):
ip.filter: removes campaigns of “greedy” IP addresses.triplet.filter: reduces triplets to a single observation.small.filter: removes entries smaller than 1,000 bytes.sequence.filter: removes blocs of past versions.size.filter: removes entries smaller than a package’s binary or source file.These filters are off by default (e.g., ip.filter = FALSE). To apply them, set the argument for the filter you want to TRUE:
Alternatively, you can simply set all.filters = TRUE.
Note that the all.filters = TRUE is contextual. Depending on the function used, you’ll either get the CRAN-specific or the package-specific set of filters. The former sets ip.filter = TRUE and size.filter = TRUE; it works independently of packages at the level of the entire log. The latter sets triplet.filter = TRUE, sequence.filter = TRUE and size.filter TRUE; it relies on package specific information (e.g., size of source or binary file).
Ideally, we’d like to use both sets. However, the package-specific set is computationally expensive because they need to be applied individually to all packages in the log, which can involve tens of thousands of packages. While not unfeasible, currently this takes a long time. For this reason, when all.filters = TRUE, packageRank(), ipPackage(), countryPackage(), countryDistribution() and packageDistribution() use only CRAN specific filters while packageLog(), packageCountry(), and filteredDownloads() use both CRAN and package specific filters.
To understand when results become availabble, you need to be aware that ‘packageRank’ has two upstream, online dependencies. The first is Posit/RStudio’s CRAN package download logs, which record traffic to the “0-Cloud” mirror at cloud.r-project.org (formerly Posit/RStudio’s CRAN mirror). The second is Gábor Csárdi’s ‘cranlogs’ R package, which uses those logs to compute the download counts of both the R application and R packages.
The CRAN package download logs for the previous day are usually be posted by 17:00 UTC and the results for ‘cranlogs’ are usually available soon after.
Occasionally problems with “today’s” data can emerge due to the upstream dependencies illustrated below.
CRAN Download Logs --> 'cranlogs' --> 'packageRank'If there’s a problem with the logs (e.g., they’re not posted on time), both ‘cranlogs’ and ‘packageRank’ will be affected. If this happens, you’ll see things like an unexpected zero count(s) for your package(s) (actually, you’ll see a zero download count for all of CRAN), data from “yesterday”, or a “Log is not (yet) on the server” error message.
'cranlogs' --> packageRank::cranDownloads()If there’s a problem with ‘cranlogs’ but not with the logs, only packageRank::cranDownalods() will be affected (the zero downloads problem). All other ‘packageRank’ functions should work since they either directly access the logs or use some other source. Usually, these errors resolve themselves the next time the underlying scripts are run (“tomorrow”, if not sooner).
logInfo()To check the status of the download logs and ‘cranlogs’, use logInfo(). This function checks whether 1) “today’s” log is posted on Posit/RStudio’s server and 2) “today’s” results have been computed by ‘cranlogs’.
$`Today's log/result`
[1] "2023-02-01"
$`Today's log posted?`
[1] "Yes"
$`Today's results on 'cranlogs'?`
[1] "No"
$status
[1] "Today's log is typically posted by 09:00 PST (01 Feb 17:00 GMT)."Because you’re typically interested in today’s log file, another thing that affects availability are time zone differences. For example, let’s say that it’s 09:01 on 01 January 2021 and you want to compute the rank percentile for ‘ergm’ for the last day of 2020. You might be tempted to use the following:
However, depending on where you make this request, you may not get the data you expect. In Honolulu, USA, you will. In Sydney, Australia you won’t. The reason is that you’ve somehow forgotten a key piece of trivia: Posit/RStudio typically posts yesterday’s log around 17:00 UTC the following day.
The expression works in Honolulu because 09:01 HST on 01 January 2021 is 19:01 UTC 01 January 2021. So the log you want has been available for 2 hours. The expression fails in Sydney because 09:01 AEDT on 01 January 2021 is 31 December 2020 22:00 UTC. The log you want won’t actually be available for another 19 hours.
To make life a little easier, ‘packageRank’ does two things. First, when the log for the date you want is not available (due to time zone rather than server issues), you’ll just get the last available log. If you specified a date in the future, you’ll either get an error message or a warning with an estimate of when the log you want should be available.
Using the Sydney example and the expression above, you’d get the results for 30 December 2020:
> date packages downloads rank percentile
> 1 2020-12-30 ergm 292 873 of 20,077 95.6If you had specified the date, you’d get an additional warning:
> date packages downloads rank percentile
> 1 2020-12-30 ergm 292 873 of 20,077 95.6
Warning message:
2020-12-31 log arrives in appox. 19 hours at 02 Jan 04:00 AEDT. Using last available!Keep in mind that 17:00 UTC is not a hard deadline. Barring server issues, the logs are usually posted before that time. I don’t know when the script starts but the posting time seems to be a function of the number of entries: closer to 17:00 UTC when there are more entries (e.g., weekdays); before 17:00 UTC when there are fewer entries (e.g., weekends). Again, barring server issues, the ‘cranlogs’ results are usually available shortly after 17:00 UTC.
Here’s what you’d see using the Honolulu example:
$`Today's log/result`
[1] "2020-12-31"
$`Today's log posted?`
[1] "Yes"
$`Today's results on 'cranlogs'?`
[1] "Yes"
$`Available log/result`
[1] "Posit/RStudio (2020-12-31); 'cranlogs' (2020-12-31)."
$status
[1] "Everything OK."The functions uses your local time zone, which depends on R’s ability to compute your local time and time zone (e.g., Sys.time() and Sys.timezone()). My understanding is that there may be operating system or platform specific issues that could undermine this ability.
The first data fix addresses a problem that affects logs from late 2012 through the beginning of 2013. To understand the problem, we need to be know that the Posit/RStudio download logs, which begin on 01 October 2012, are stored as separate files with a name/URL that embeds the date:
http://cran-logs.rstudio.com/2022/2022-01-01.csv.gzFor the logs in question, this convention was broken in three ways: 1) some logs are effectively duplicated (same log, multiple names), 2) at least one is mislabeled and 3) the logs from 13 October through 28 December are offset by +3 days (e.g., the file with the name/URL “2012-12-01” contains the log for “2012-11-28”). As a result, we get erroneous download counts and we actually lose the last three logs of 2012. Details are available here.
Unsurprisingly, all this leads to erroneous download counts. What is surprising is that these errors are compounded by how ‘cranlogs’ computes package downloads.
fixDate_2012()‘packageRank’ functions like packageRank() and packageLog() are affected by the second and third defects (mislabeled and offset logs) because they access logs via their filename/URL. fixDate_2012() addresses the problem by re-mapping problematic logs so that you get the log you expect.
fixCranlogs()In contrast, while unaffected by the second and third defects functions that rely on cranlogs::cran_download() (e.g., packageRank::cranDownloads()`, ‘adjustedcranlogs’ and ‘dlstats’) are susceptible to the first defect (duplicate names). My understanding is that this is because ‘cranlogs’ uses the date in a log rather than the filename/URL to retrieve logs.
To put it differently, ‘cranlogs’ can’t detect multiple instances of logs with the same date. I found 3 logs with duplicate filename/URLs, and 5 additional instances of overcounting (including one of tripling).
fixCranlogs() addresses this overcounting problem by recomputing the download counts using the actual log(s) when any of the eight problematic dates are requested. Details about the 8 days and fixCranlogs() can be found here.
The second data fix addresses a problem of more recent vintage. From 2023-09-13 through 2023-10-02, the download counts for the R application returned by cranlogs::cran_downloads(packages = "R"), is, with two exceptions, twice what one would expect when looking at the actual log(s). The two exceptions are: 1) 2023-09-28 where the counts are identical but for a “rounding error” possibly due to an NA value and 2) 2023-09-30 where there is actually a three-fold difference.
Here are the relevant ratios of counts comparing ‘cranlogs’ results with counts based on the underlying logs:
2023-09-12 2023-09-13 2023-09-14 2023-09-15 2023-09-16 2023-09-17 2023-09-18 2023-09-19
osx 1 2 2 2 2 2 2 2
src 1 2 2 2 2 2 2 2
win 1 2 2 2 2 2 2 2
2023-09-20 2023-09-21 2023-09-22 2023-09-23 2023-09-24 2023-09-25 2023-09-26 2023-09-27
osx 2 2 2 2 2 2 2 2
src 2 2 2 2 2 2 2 2
win 2 2 2 2 2 2 2 2
2023-09-28 2023-09-29 2023-09-30 2023-10-01 2023-10-02 2023-10-03
osx 1.000000 2 3 2 2 1
src 1.000801 2 3 2 2 1
win 1.000000 2 3 2 2 1Details and code for replication can be found in issue #69. fixRCranlogs() corrects the discrepancies.
Note that there was a similar issue for package download counts around the same period but that is now fixed in ‘cranlogs’. For details, see issue #68
For those interested in directly using the Posit/RStudio download logs, this section describes some issues that may be of use.
While IP addresses are anonymized, packageCountry() and countryPackage() make use of the fact that the logs provide corresponding ISO country codes or top level domains (e.g., AT, JP, US). Note that coverage extends to about 85% of observations (i.e., approximately 15% country codes are NA). Also, for what it’s worth, there seems to be a a couple of typos for country codes: “A1” (A + number one) and “A2” (A + number 2). According to Posit/RStudio’s documentation, this coding was done using MaxMind’s free database, which no longer seems to be available and may be a bit out of date.
To avoid the bottleneck of downloading multiple log files, packageRank() is currently limited to individual calendar dates. To reduce the bottleneck of re-downloading logs, which can approach 100 MB, ‘packageRank’ makes use of memoization via the ‘memoise’ package.
Here’s relevant code:
fetchLog <- function(url) data.table::fread(url)
mfetchLog <- memoise::memoise(fetchLog)
if (RCurl::url.exists(url)) {
cran_log <- mfetchLog(url)
}
# Note that data.table::fread() relies on R.utils::decompressFile().This means that logs are intelligently cached; those that have already been downloaded in your current R session will not be downloaded again.
With R 4.0.3, the timeout value for internet connections became more explicit. Here are the relevant details from that release’s “New features”:
The default value for options("timeout") can be set from environment variable
R_DEFAULT_INTERNET_TIMEOUT, still defaulting to 60 (seconds) if that is not set
or invalid.This change can affect functions that download logs. This is especially true over slower internet connections or when you’re dealing with large log files. To fix this, fetchCranLog() will, if needed, temporarily set the timeout to 600 seconds.
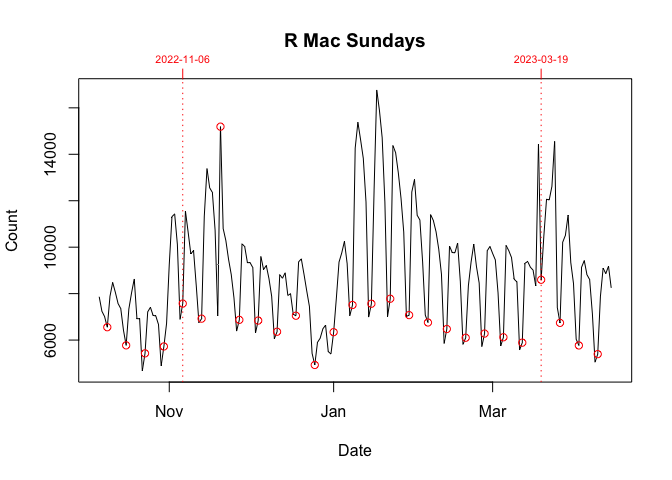
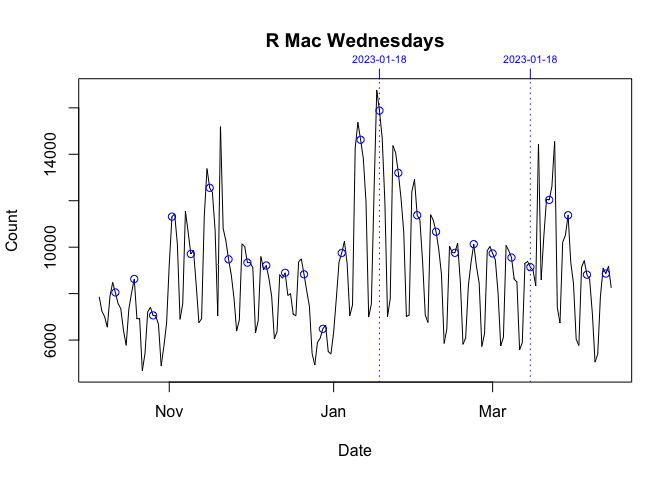
The graph above for R downloads shows the daily downloads of the R application broken down by platform (Mac, Source, Windows). In it, you can see the typical weekly pattern of mid-week peaks and weekend troughs.
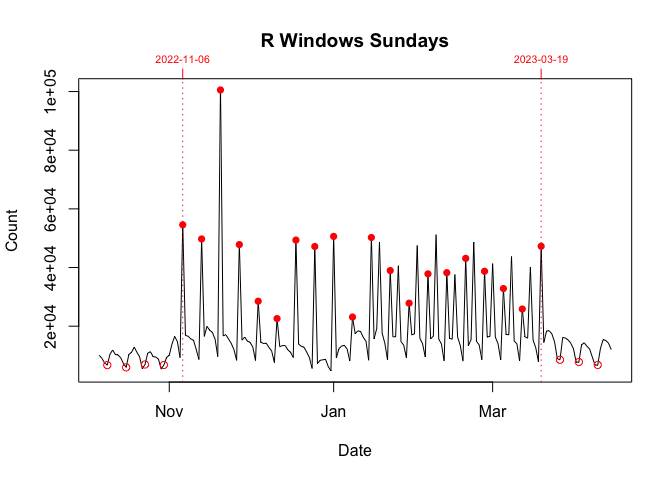
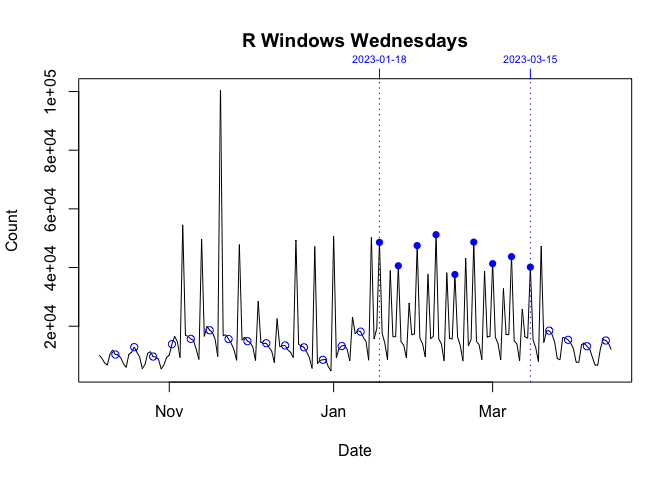
However between 06 November 2022 and 19 March 2023, this was broken. On Sundays (06 November 2022 - 19 March 2023) and Wednesdays (18 January 2023 - 15 March 2023), there were noticeable, repeated orders-of-magnitude spikes in the daily downloads of the Windows version of R.
plot(cranDownloads("R", from = "2022-10-06", to = "2023-04-14"))
axis(3, at = as.Date("2022-11-06"), labels = "2022-11-06", cex.axis = 2/3,
padj = 0.9)
axis(3, at = as.Date("2023-03-19"), labels = "2023-03-19", cex.axis = 2/3,
padj = 0.9)
abline(v = as.Date("2022-11-06"), col = "gray", lty = "dotted")
abline(v = as.Date("2023-03-19"), col = "gray", lty = "dotted")
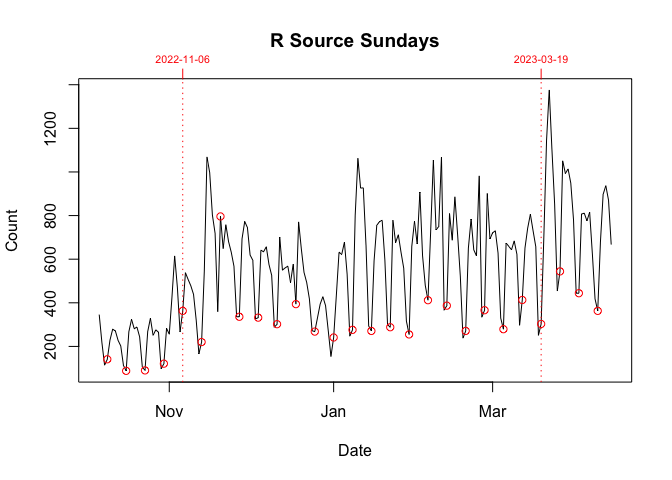
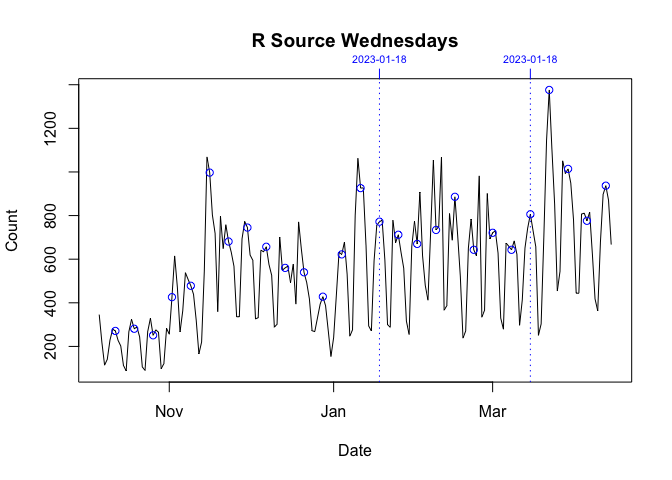
These download spikes did not seem to affect either the Mac or Source versions. I show this in the graphs below. Each plot, which is individually scaled, breaks down the data in the graph above by day (Sunday or Wednesday) and platform.
The key thing is to compare the data in the period bounded by vertical dotted lines with the data before and after. If a Sunday or Wednesday is orders-of-magnitude unusual, I plot that day with a filled rather than an empty circle. Only Windows, the final two graphs below, earn this distinction.